
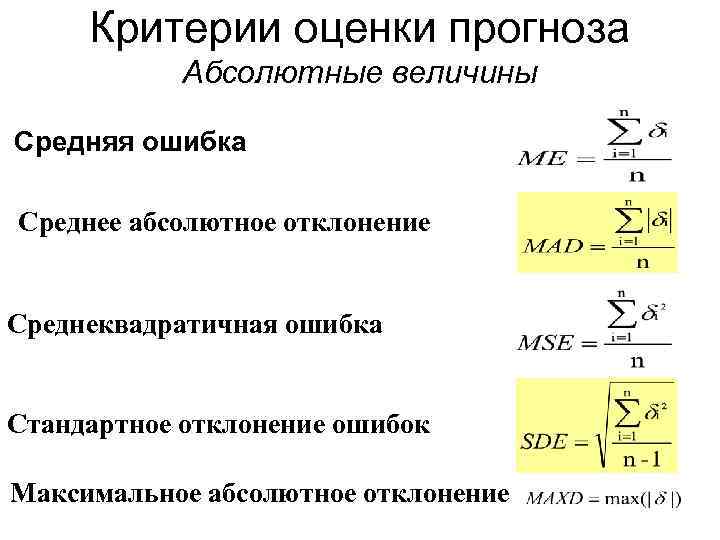
Средняя квадратическая ошибка
средняя квадратическая ошибка или MSE, рассчитывается как среднее значение квадратов ошибок прогноза. Возведение в квадрат значений ошибки прогноза заставляет их быть положительными; это также приводит к большему количеству ошибок.
Квадратные ошибки прогноза с очень большими или выбросами возводятся в квадрат, что, в свою очередь, приводит к вытягиванию среднего значения квадратов ошибок прогноза, что приводит к увеличению среднего квадрата ошибки. По сути, оценка дает худшую производительность тем моделям, которые делают большие неверные прогнозы.
Мы можем использовать mean_squared_error () функция из scikit-learn для вычисления среднеквадратичной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
При выполнении примера вычисляется и выводится среднеквадратическая ошибка для списка ожидаемых и прогнозируемых значений.
Значения ошибок приведены в квадратах от предсказанных значений. Среднеквадратичная ошибка, равная нулю, указывает на совершенное умение или на отсутствие ошибки.
16.
Практика решения ЗЛП
1 часть – Построение математических моделей линейного
программирования
Математические модели линейного программирования строятся
на основе содержательной постановки экономической задачи.
Пример.
Типичная задача распределения ресурсов ставится следующим
образом.
Пусть фирма выпускает продукцию четырех типов Продукт1,
Продукт2, Продукт3, Продукт4, для изготовления которой
требуются ресурсы трех видов: трудовые, сырье, финансы.
Количество ресурса каждого вида, необходимое для выпуска
единицы продукции данного типа, называется нормой расхода.
Исходные данные.
Норма расхода, а также прибыль, получаемая от реализации
единицы каждого типа продукции, приведены в таблице 1, там же
приведен объем ресурса, которым можно располагать. Требуется
определить, в каком количестве надо выпускать продукцию
каждого
типа,
чтобы
суммарная
прибыль
была
максимальной.
Определение и основные принципы
Аппроксимация в Excel — это процесс анализа и обработки данных, в ходе которого строится математическая модель или функция, которая наилучшим образом приближает эти данные.
Основная цель аппроксимации — найти простую аналитическую формулу, которая будет приближать экспериментальные данные с минимальной погрешностью. Аппроксимация может быть полиномиальной, тригонометрической, экспоненциальной или любой другой функцией.
В Excel для аппроксимации данных можно использовать различные методы, такие как метод наименьших квадратов, интерполяция, экстраполяция и другие. Метод наименьших квадратов — это метод, при котором минимизируется сумма квадратов расстояний между экспериментальными данными и значениями, предсказанными моделью.
- Анализ данных. Прежде чем приступить к аппроксимации, необходимо проанализировать имеющиеся данные, определить их свойства, выбрать подходящую модель и метод аппроксимации.
- Построение графика. Перед началом процесса аппроксимации данных, полезно построить график зависимости исходных данных. Это позволит визуально оценить тип зависимости и проверить, соответствует ли выбранная модель представленным данным.
- Выбор модели. В зависимости от типа данных и требуемой точности аппроксимации, нужно выбрать подходящую математическую модель. Например, для линейной зависимости можно выбрать модель прямой линии (y = kx + b), а для нелинейной зависимости могут подходить экспоненциальные или логарифмические функции.
- Расчет параметров модели. Для построения модели необходимо рассчитать ее параметры. Это может быть выполнено с использованием различных методов, таких как метод наименьших квадратов или численные методы оптимизации.
- Оценка точности модели. После построения модели, необходимо оценить ее точность с использованием различных критериев. Это позволит проверить, насколько хорошо модель приближает исходные данные.
- Прогнозирование значений. После того, как модель была построена и ее точность оценена, можно использовать модель для прогнозирования значений. Это позволяет предсказать значения вне известного диапазона данных или в будущем времени.
Аппроксимация в Excel является полезным инструментом для анализа и обработки данных. Этот процесс позволяет упростить и интерпретировать сложные зависимости между переменными и использовать их для прогнозирования будущих значений.
Тогда средняя ошибка аппроксимации равна
Таблица 3.1 – Исходные данные
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | ||
| Рязанская | ||
| Смоленская | ||
| Тверская | ||
| Тульская | ||
| Ярославская |
Эмпирические коэффициенты регрессии b, b1 будем определять с помощью инструмента «Регрессия» надстройки «Анализ данных» табличного процессораMS Excel.
Алгоритм определения коэффициентов состоит в следующем.
1. Вводимисходные данные в табличный процессор MS Excel.
2. Вызываемнадстройку Анализ данных(рисунок 2).
3.Выбираем инструмент анализа Регрессия(рисунок 3).
4. Заполняем соответствующие позиции окна Регрессия (рисунок 4).
5. Нажимаем кнопку ОК окна Регрессия и получаем протокол решения задачи (рисунок 5)
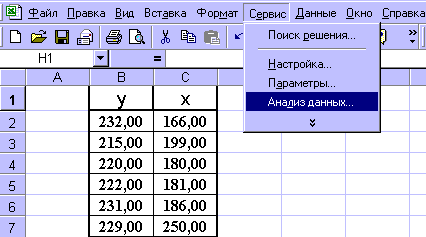 |
Рисунок 2 – Активизация надстройки Анализ данных
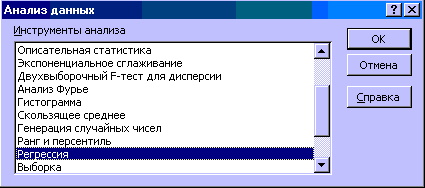 |
Рисунок 3 – Выбор инструмента Регрессия
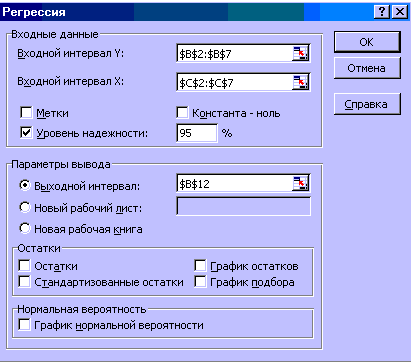 |
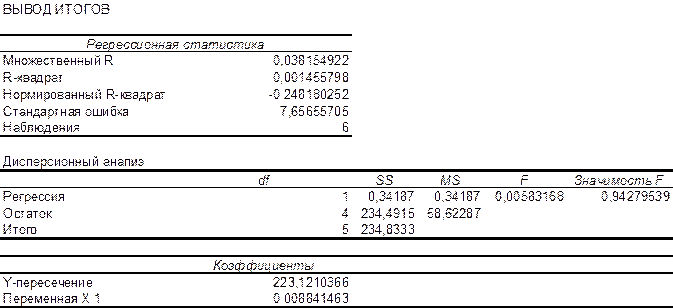 Рисунок 4 – Окно Регрессия
Рисунок 4 – Окно Регрессия
Рисунок 5 – Протокол решения задачи
Из рисунка 5 видно, что эмпирические коэффициенты регрессии соответственно равны
b1 = 0, 0088.
Тогда уравнение парной линейной регрессии, связывающая величину ежемесячной пенсии у с величиной прожиточного минимумахимеет вид
.(3.2)










Далее, в соответствии с заданием необходимо оценить тесноту статистической связи между величиной прожиточного минимума х и величиной ежемесячной пенсии у. Эту оценку можно сделать с помощью коэффициента корреляции . Величина этого коэффициента на рисунке 5 обозначена как множественный R и соответственно равна 0,038. Поскольку теоретически величина данного коэффициента находится в пределахот –1 до +1, то можно сделать вывод о не существенности статистической связимежду величиной прожиточного минимума х и величиной ежемесячной пенсии у.
Параметр «R – квадрат», представленныйна рисунке 5 представляет собой квадрат коэффициента корреляции и называется коэффициентом детерминации. Величина данного коэффициента характеризует долю дисперсии зависимой переменной у, объясненную регрессией (объясняющей переменной х). Соответственно величина 1- характеризует долю дисперсии переменной у, вызванную влиянием всех остальных, неучтенных в эконометрической модели объясняющих переменных. Из рисунка 5 видно, что доля всех неучтенных в полученной эконометрической модели объясняющих переменных приблизительно составляет 1- 0,00145 = 0,998 или 99,8%.
На следующем этапе, в соответствии с заданием необходимо определить степень связи объясняющей переменной х с зависимой переменной у, используя коэффициент эластичности. Коэффициент эластичности для модели парной линейной регрессии определяется в виде:
. (3.3)
Следовательно, при изменении прожиточного минимума на 1% величина ежемесячной пенсии изменяется на 0,000758%.
Далее определяем среднюю ошибку аппроксимации по зависимости
. (3.4)
Для этого исходную таблицу 1 дополняем двумя колонками, в которых определяем значения, рассчитанные с использованием зависимости (3.2) и значения разности .
Таблица 3.2. Расчет средней ошибки аппроксимации.
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х | ||
| Орловская | 0,032 | |||
| Рязанская | 0,045 | |||
| Смоленская | 0,021 | |||
| Тверская | 0,012 | |||
| Тульская | 0,028 | |||
| Ярославская | 0,017 | |||
| S=0,155 |
Тогда средняя ошибка аппроксимации равна
.
Из практики известно, что значение средней ошибки аппроксимации не должно превышать (12…15)%
На последнем этапе выполним оценкустатистической надежности моделирования спомощью F – критерия Фишера. Для этого выполним проверку нулевой гипотезы Н о статистической не значимости полученного уравнения регрессиипо условию:
если при заданном уровне значимости a = 0,05 теоретическое (расчетное) значение F-критерия больше его критического значения Fкрит (табличного), то нулевая гипотеза отвергается, и полученное уравнение регрессии принимается значимым.
Из рисунка 5 следует, что Fрасч = 0,0058. Критическое значение F-критерия определяем с помощью использования статистической функции FРАСПОБР (рисунок 6). Входными параметрами функции является уровень значимости (вероятность) и число степеней свободы 1 и 2. Для модели парной регрессии число степеней свободы соответственно равно 1 (одна объясняющая переменная) и n-2 = 6-2=4.
 |
Рисунок 6 – Окно статистической функции FРАСПОБР
Из рисунка 6 видно, что критическое значение F-критерия равно 7,71.
Аппроксимация в Excel статистических данных аналитической функцией.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
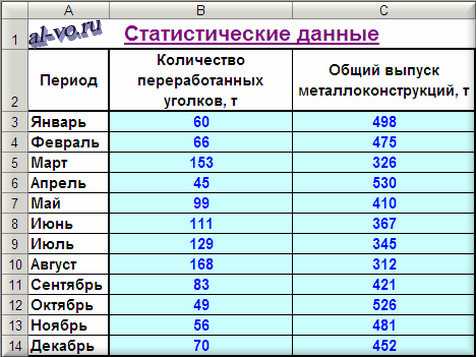
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
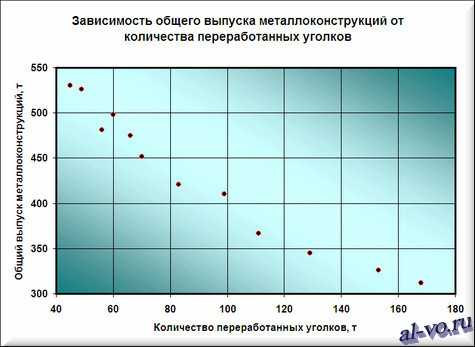
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».

5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
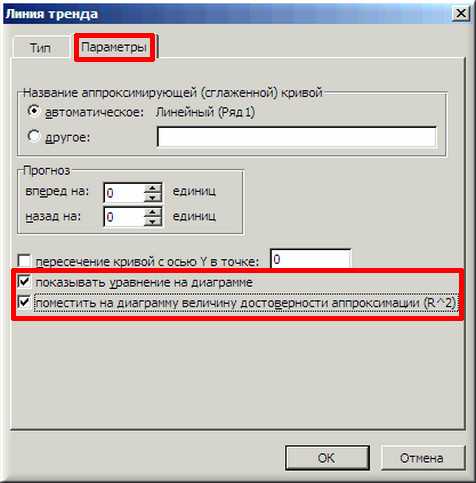
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
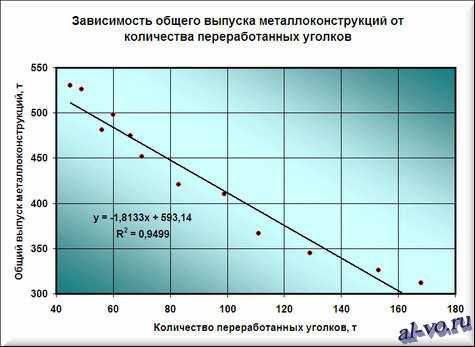
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
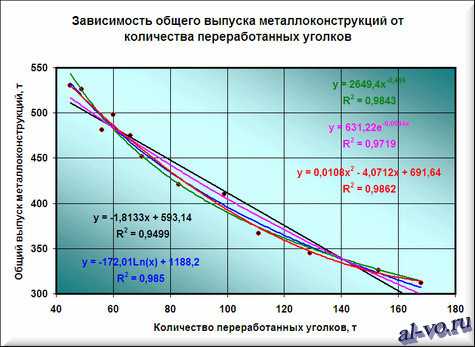
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R2.
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…
Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл
Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
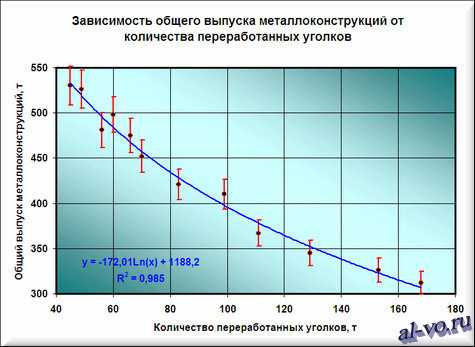
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.

10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.











Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
Шаг 2
Так как мы рассматриваем аддитивную модель вида:
Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и значениями скользящей средней St+Et = Yt-Tt, так как Yt и Tt мы уже знаем.
Используем оценки сезонной компоненты (St+Et) для расчета значений сезонной компоненты St. Для этого найдем средние за каждый интервал (по всем годам) оценки сезонной компоненты St.
Средняя оценка сезонной компоненты находится как сумма по столбцу, деленная на количество заполненных строк в этом столбце. В нашем случае оценки сезонной составляющей расположились в строках без пересечений, поэтому сумма по столбцам состоит из одиночных значений, следовательно и среднее будет таким же. Если бы мы располагали периодом побольше, например с 2015, у нас бы добавилась еще одна строка и мы смогли бы полноценно найти среднее, поделив сумму на 2.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем интервалам должна быть равна нулю. Поэтому найдя значение случайной составляющей, поделив сумму средних оценок сезонной составляющей на 12, мы вычитаем ее значение из каждой средней оценки и получаем скорректированную сезонную компоненту, St.
Далее, заполняем нашу таблицу значениями сезонной составляющей дублируя ряд каждые 12 месяцев, то есть три раза:
Что будем делать с полученным материалом:
Все темы данного раздела:
Состав исходной информации
Основной базой исходной информации для эконометрических исследований служат данные статистики либо данные бухгалтерского учета. Исследуемые эконометрикой взаимосвязи стохастичны по своей природе, т
Интерполяционный полином Лагранжа
Пусть имеется зависимость y = f(x) между величинами x и y, для которой нам известны отдельные точки (xi,yi), i = 0,1,2,…,
Случай 1.
Через одну точку (x0, y0) можно провести пучок прямых
y = y0+b(x-x0) (2.1)
(а также вертикальную пря
Случай 2.
Через две различные точки (x0,y0), (x1,y1) проходит одна и только одна прямая. Если x0 ¹
Случай 3.
Многочлен второй степени (квадратичная функция), график которой проходит через три точки (x0,y0), (x1,y1), (x2
Случай n.
Теперь ясно, что интерполяционный полином Лагранжа n-ой степени, график которого проходит через n+1 точку (xi,yi), i=0,1,2,…,n, можно записать в ви
Парная линейная регрессия. Метод наименьших квадратов
Пусть имеется n пар чисел (xi, yi), i=1,2,…,n, относительно которых предполагается, что они отвечают линейной зависимости между величинами x и y:
Множественная линейная регрессия
Парная регрессия может дать хороший результат при моделировании, если влиянием других факторов, воздействующих на объект исследования, можно пренебречь. Но, существует обычно нескол
Нелинейные модели
Мы изучили применение метода наименьших квадратов для определения параметров, которые входят в функциональные зависимости линейно. Поэтому для них в параграфах 3 и 4 получились сист
Системы одновременных эконометрических уравнений
Объектом статистического изучения в социально-экономических науках являются сложные системы. Измерение тесноты связей между переменными, построение изолированных уравнений регрессии
Составляющие временного ряда
Временной ряд x(t) – это множество значений величины x, отвечающих последовательности моментов времени t, т.е. это функция tx(t), которая обычно считает
Определение составляющих временного ряда
Одним из наиболее распространенных способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость последовательных значений
При этом коэффициенты ak, bk будут равны
Если функция x (t) четная, т.е. выполняется равенство x (-t) = x (t), то в
Временной ряд как случайный процесс
Пусть значение экономического показателя x(t) в любой момент времени t представляет собой случайную величину X (t). Предположим, что слу
Модели ARIMA
В эконометрике анализ временных рядов с использованием оценки спектральной плотности (спектральный анализ) играет, как правило, вспомогательную роль, помогая установить периоды хара
Учет сезонных составляющих
Обобщение модели ARIMA, позволяющие учесть периодические (сезонные) составляющие временного ряда было предложено Дж. Боксом и Г. Дженкинсом . Этот метод реализован в систе
Анализ погрешностей исходной информации
Значения экономических показателей обычно известны неточно, с некоторой погрешностью. Рассмотрим основные правила обработки данных, содержащих погрешности, или ошибки измерений. Пус
Доверительные интервалы
Введем случайную величину. (13.1)
Нетрудно проверить, что xÎN(0,1), вследствие ч
Расчет погрешностей
Эмпирические данные часто подвергаются математической обработке – над ними
выполняются арифметические операции сложения, вычитания, умножения и деления, в некоторых случаях
Коэффициент детерминации
Коэффициент детерминации характеризует качество регрессионной модели.
Значения различных величин, получ
Принцип максимального правдоподобия. Построение регрессионных моделей при гетероскедастичности ошибок
Для нахождения неизвестных величин по результатам измерений, содержащих случайные погрешности, служит метод наименьших квадратов (МНК). Определяемые величины обычно связаны уравнениями, образующими
Статистические гипотезы
В предыдущих параграфах рассматривалась методика моделирования взаимосвязей экономических показателей и процессов. С помощью полученных уравнений регрессии моделировалась эта связь.
F – статистика
Значимость регрессионной модели определяется с помощью F-критерия Фишера. Для этого вычисляется отношение
T – статистика
Для оценки значимости отдельных параметров регрессионной модели y=a+bx+e их величина сравнивается с их стандартной ошибкой. При этом рассчитывается так называемый
Как рассчитать среднеквадратичную ошибку в Excel
В Excel нет встроенной функции для расчета RMSE, но мы можем довольно легко вычислить его с помощью одной формулы. Мы покажем, как рассчитать RMSE для двух разных сценариев.
Сценарий 1
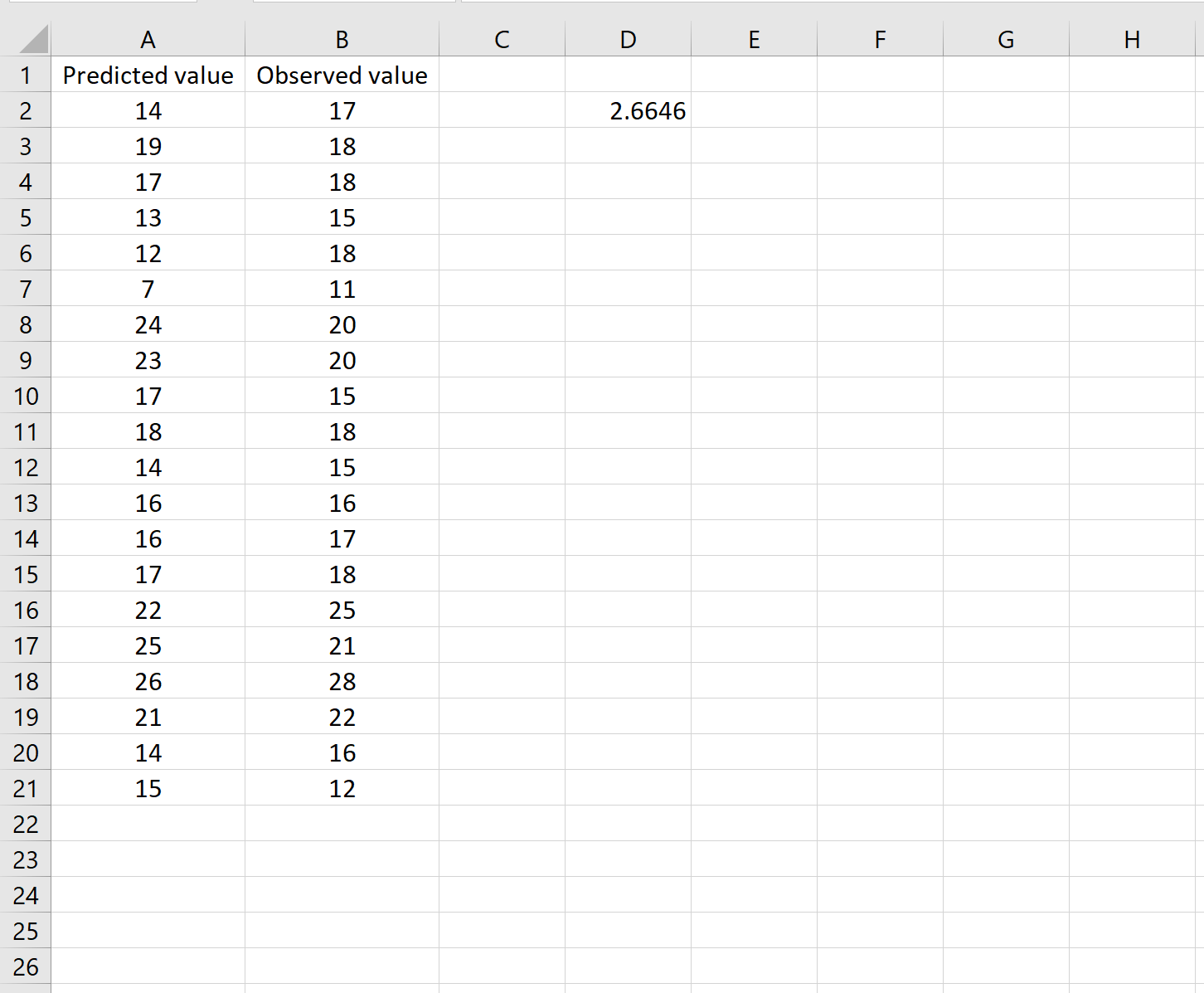
В одном сценарии у вас может быть один столбец, содержащий предсказанные значения вашей модели, и другой столбец, содержащий наблюдаемые значения. На изображении ниже показан пример такого сценария:

Если это так, то вы можете рассчитать RMSE, введя следующую формулу в любую ячейку, а затем нажав CTRL+SHIFT+ENTER:
=КОРЕНЬ(СУММСК(A2:A21-B2:B21) / СЧЕТЧ(A2:A21))
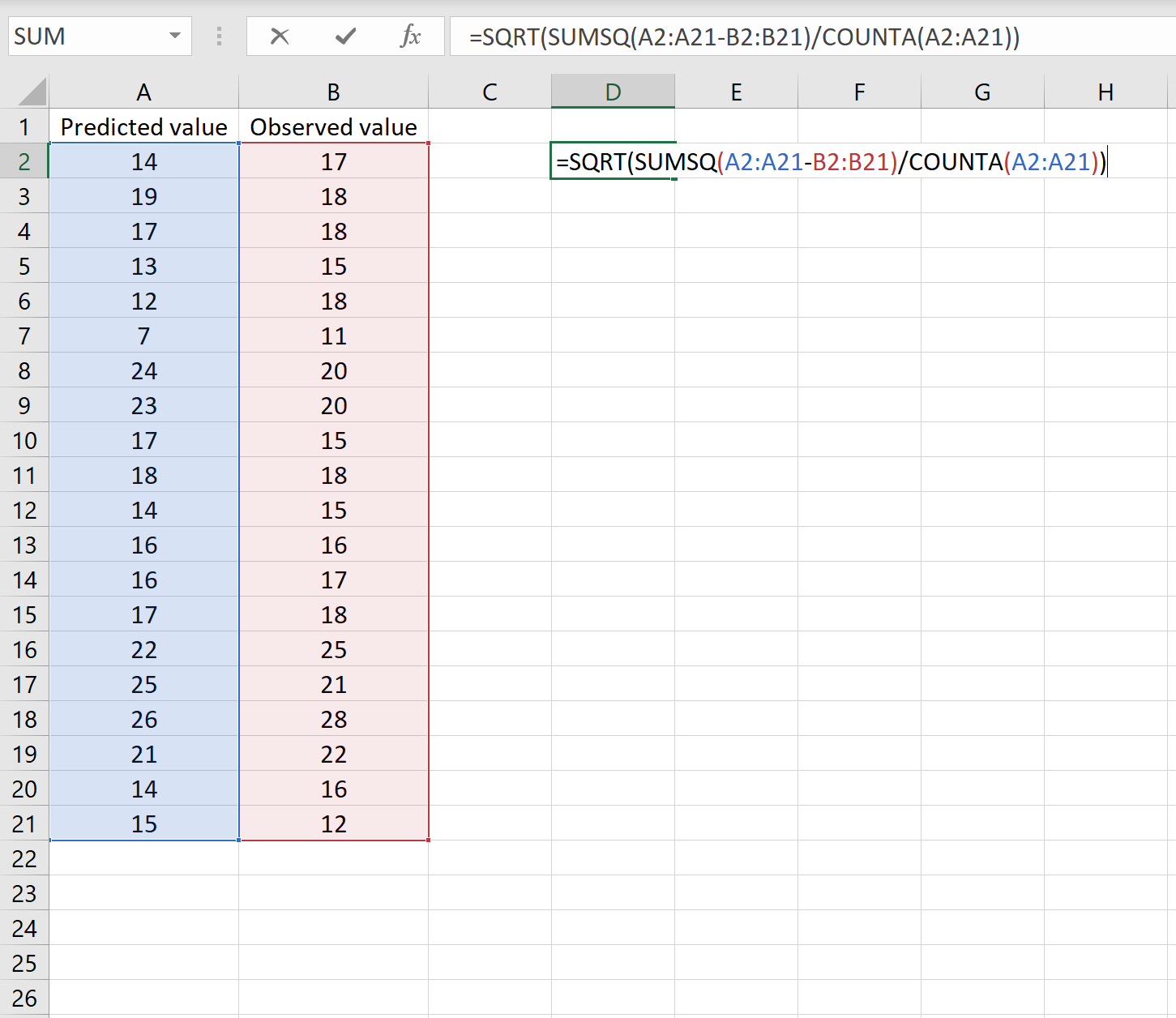
Это говорит нам о том, что среднеквадратическая ошибка равна 2,6646 .
Формула может показаться немного сложной, но она имеет смысл, если ее разобрать:
= КОРЕНЬ( СУММСК(A2:A21-B2:B21) / СЧЕТЧ(A2:A21) )
- Во-первых, мы вычисляем сумму квадратов разностей между прогнозируемыми и наблюдаемыми значениями, используя функцию СУММСК() .
- Затем мы делим на размер выборки набора данных, используя COUNTA() , который подсчитывает количество непустых ячеек в диапазоне.
- Наконец, мы извлекаем квадратный корень из всего вычисления, используя функцию SQRT() .
Сценарий 2
В другом сценарии вы, возможно, уже вычислили разницу между прогнозируемыми и наблюдаемыми значениями. В этом случае у вас будет только один столбец, отображающий различия.










На изображении ниже показан пример этого сценария. Прогнозируемые значения отображаются в столбце A, наблюдаемые значения — в столбце B, а разница между прогнозируемыми и наблюдаемыми значениями — в столбце D:
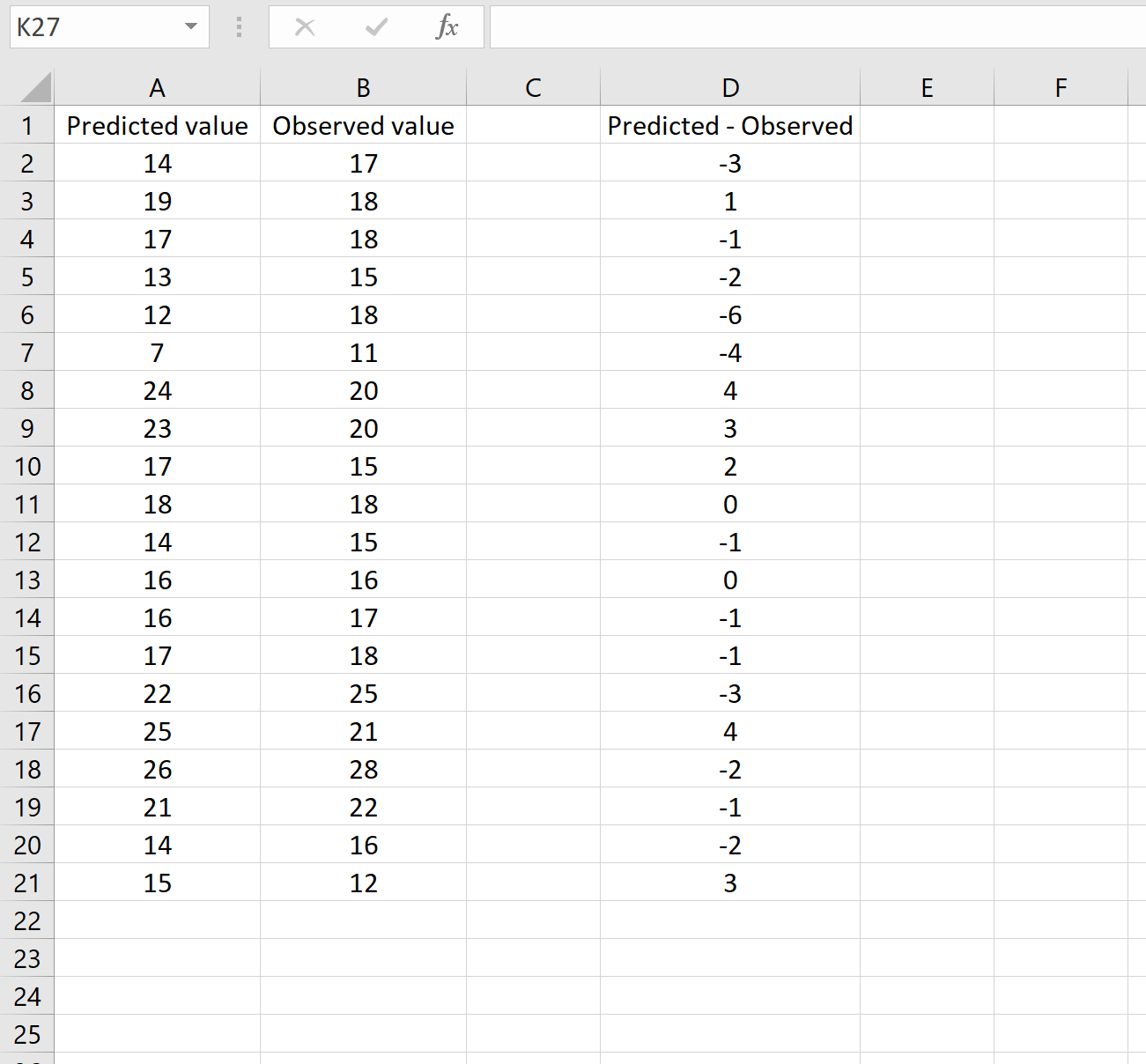
Если это так, то вы можете рассчитать RMSE, введя следующую формулу в любую ячейку, а затем нажав CTRL+SHIFT+ENTER:
=КОРЕНЬ(СУММСК(D2:D21) / СЧЕТЧ(D2:D21))

Это говорит нам о том, что среднеквадратическая ошибка равна 2,6646 , что соответствует результату, полученному в первом сценарии. Это подтверждает, что эти два подхода к расчету RMSE эквивалентны.

Формула, которую мы использовали в этом сценарии, лишь немного отличается от той, что мы использовали в предыдущем сценарии:
= КОРЕНЬ (СУММСК(D2 :D21) / СЧЕТЧ(D2:D21) )
- Поскольку мы уже рассчитали разницу между предсказанными и наблюдаемыми значениями в столбце D, мы можем вычислить сумму квадратов разностей с помощью функции СУММСК().только со значениями в столбце D.
- Затем мы делим на размер выборки набора данных, используя COUNTA() , который подсчитывает количество непустых ячеек в диапазоне.
- Наконец, мы извлекаем квадратный корень из всего вычисления, используя функцию SQRT() .
Справочная информация
ДокументыЗаконыИзвещенияУтверждения документовДоговораЗапросы предложенийТехнические заданияПланы развитияДокументоведениеАналитикаМероприятияКонкурсыИтогиАдминистрации городовПриказыКонтрактыВыполнение работПротоколы рассмотрения заявокАукционыПроектыПротоколыБюджетные организацииМуниципалитетыРайоныОбразованияПрограммыОтчетыпо упоминаниямДокументная базаЦенные бумагиПоложенияФинансовые документыПостановленияРубрикатор по темамФинансыгорода Российской Федерациирегионыпо точным датамРегламентыТерминыНаучная терминологияФинансоваяЭкономическаяВремяДаты2015 год2016 годДокументы в финансовой сферев инвестиционной
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых
переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь
на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!