
Как найти математическое ожидание в Excel?
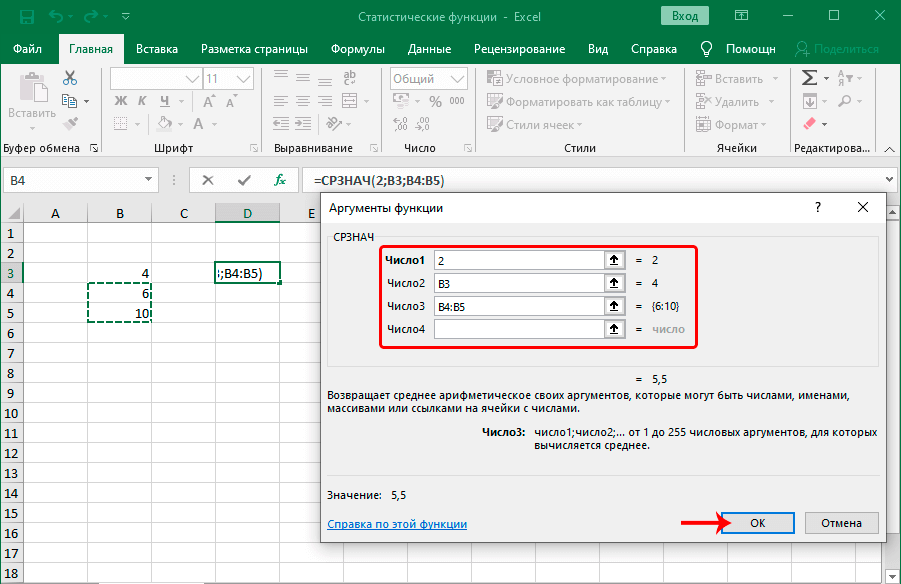
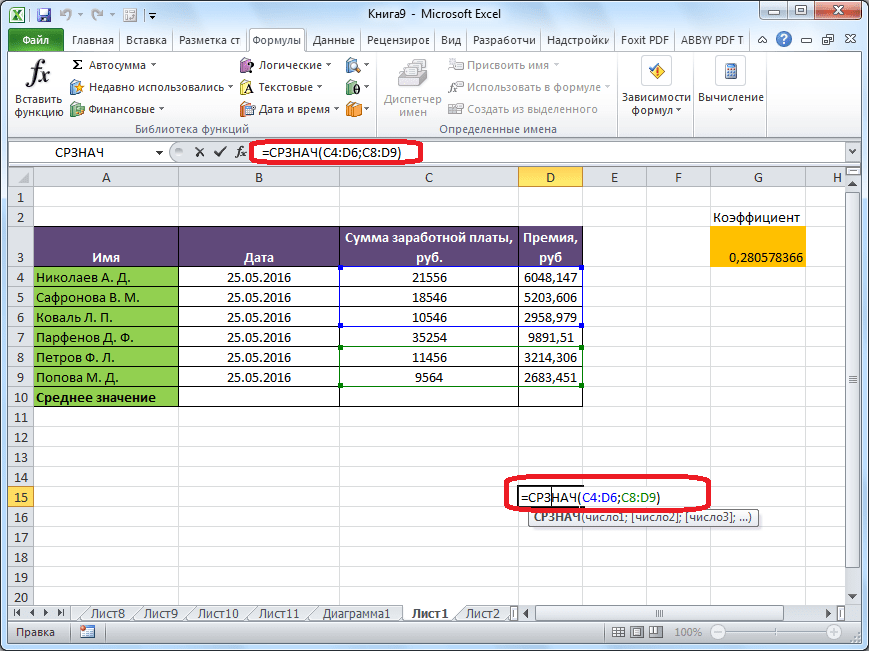
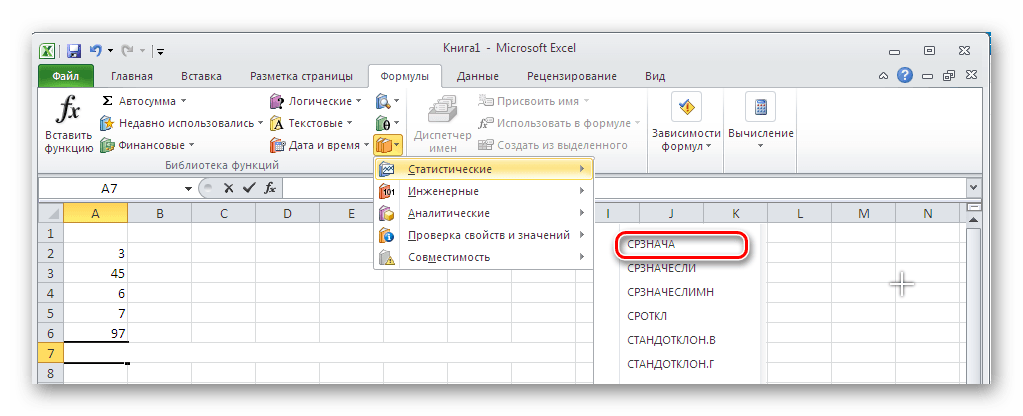
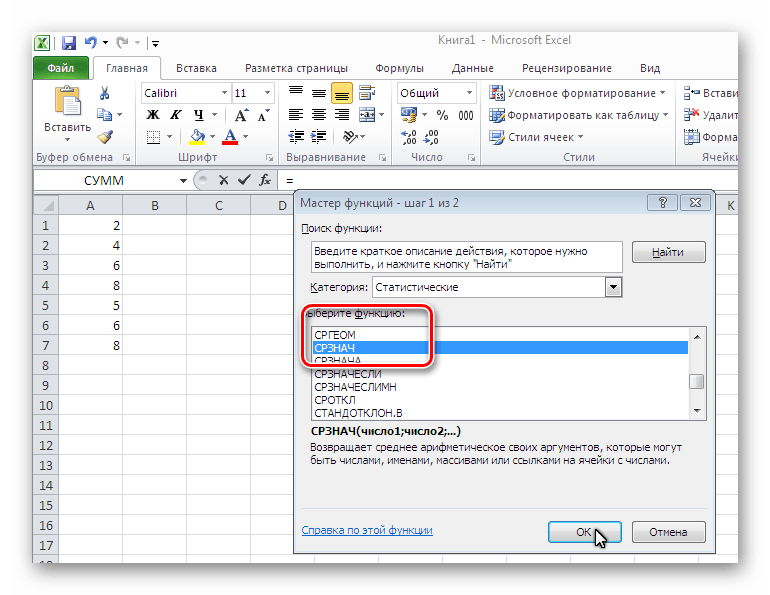
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки . Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см.
Как найти математическое ожидание пример?
Формула среднего случайной величины Математическое ожидание дискретной случайной величины Х вычисляется как сумма произведений значений xi , которые принимает СВ Х, на соответствующие вероятности pi: M(X)=n∑i=1xi⋅pi.
Как найти математическое ожидание?
Чтобы найти математическое ожидание случайной величины, следует вычислить сумму парных произведений всех возможных значений случайной величины на соответствующие им вероятности.
Как найти мат ожидание произведения?
Математическое ожидание произведения двух или нескольких взаимно независимых случайных величин равно произведению математических ожиданий этих величин. М(XY) = M(X) × M(Y). Постоянный множитель можно выносить за знак математического ожидания: M(C×X)=C×M(X).
Как рассчитать дисперсию в Excel?
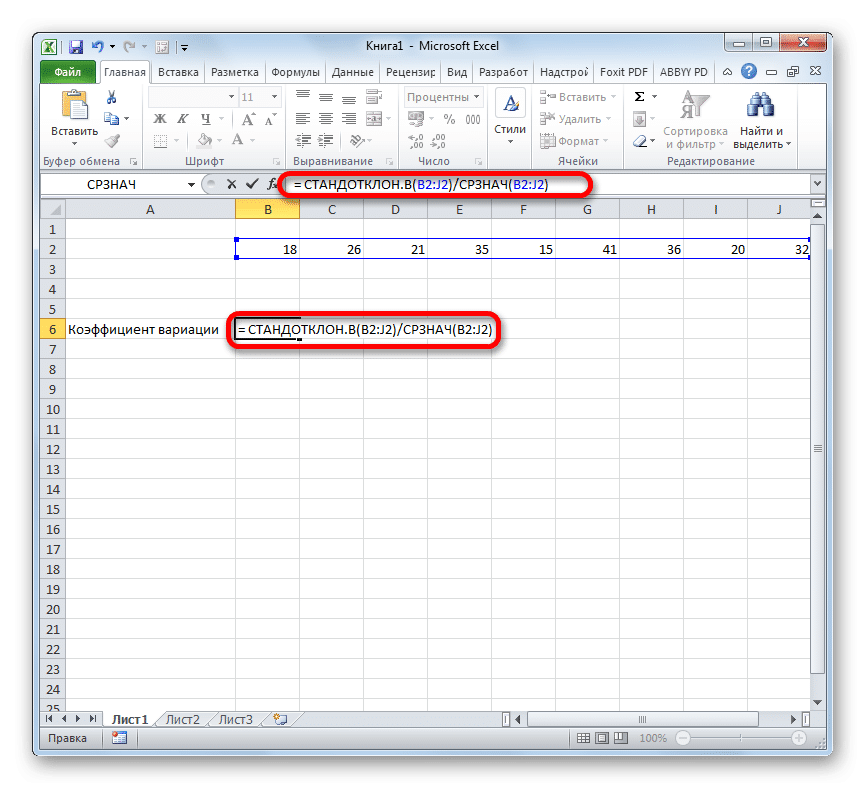
Для распределений, представленных в MS EXCEL , дисперсию можно вычислить аналитически, как функцию от параметров распределения. Например, для Биномиального распределения дисперсия равна произведению его параметров: n*p*q. Примечание : Дисперсия, является вторым центральным моментом , обозначается D, VAR(х), V(x).
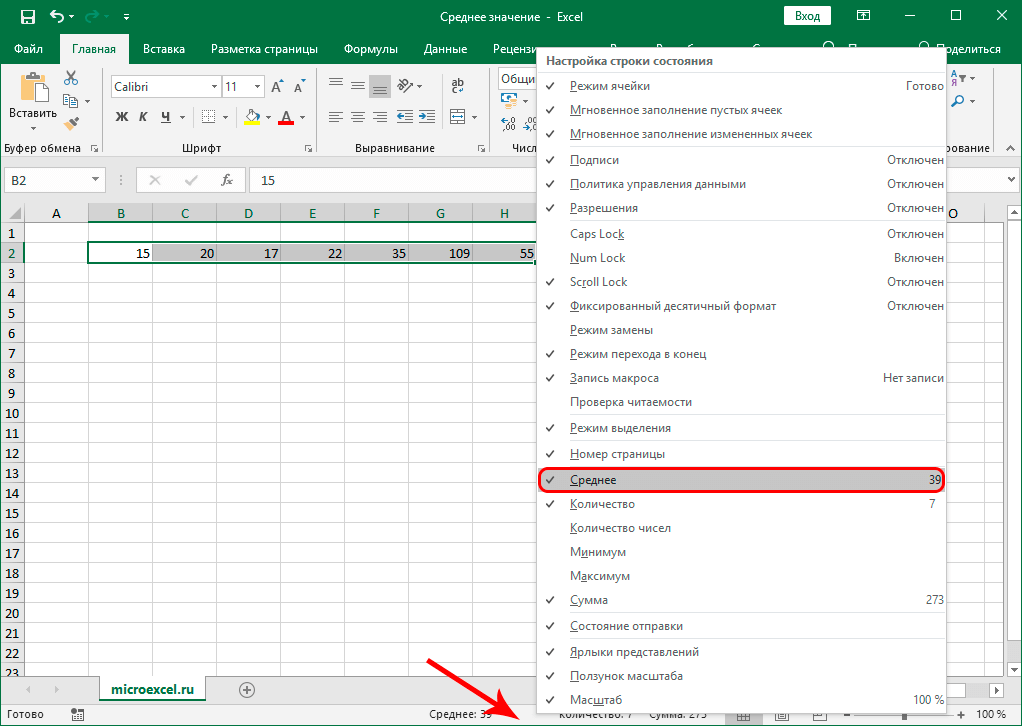
Как вычислить среднюю арифметическую в Эксель?
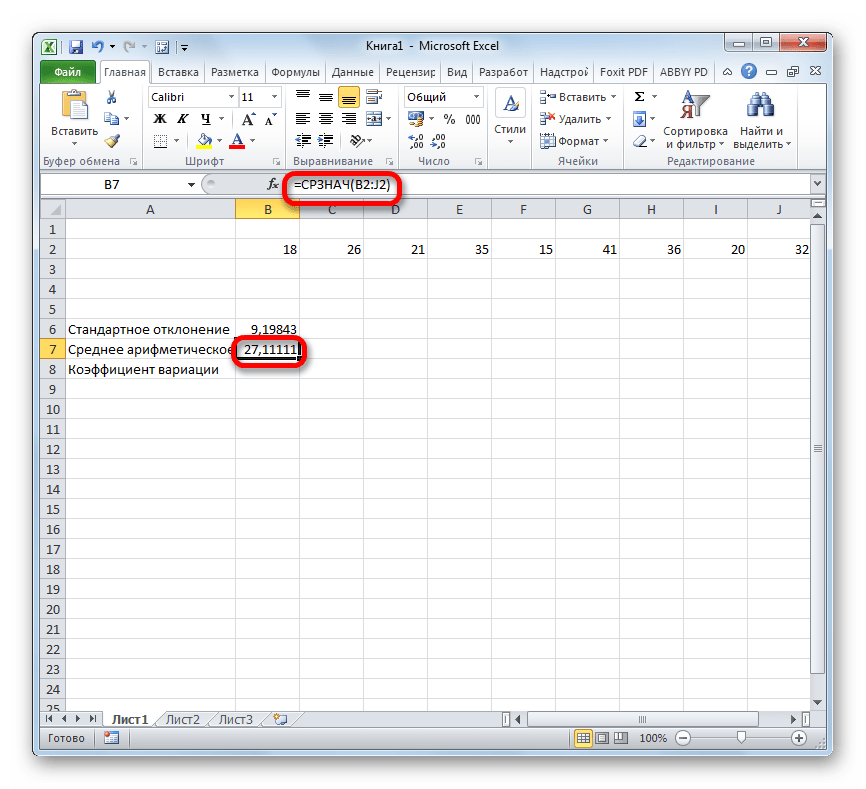
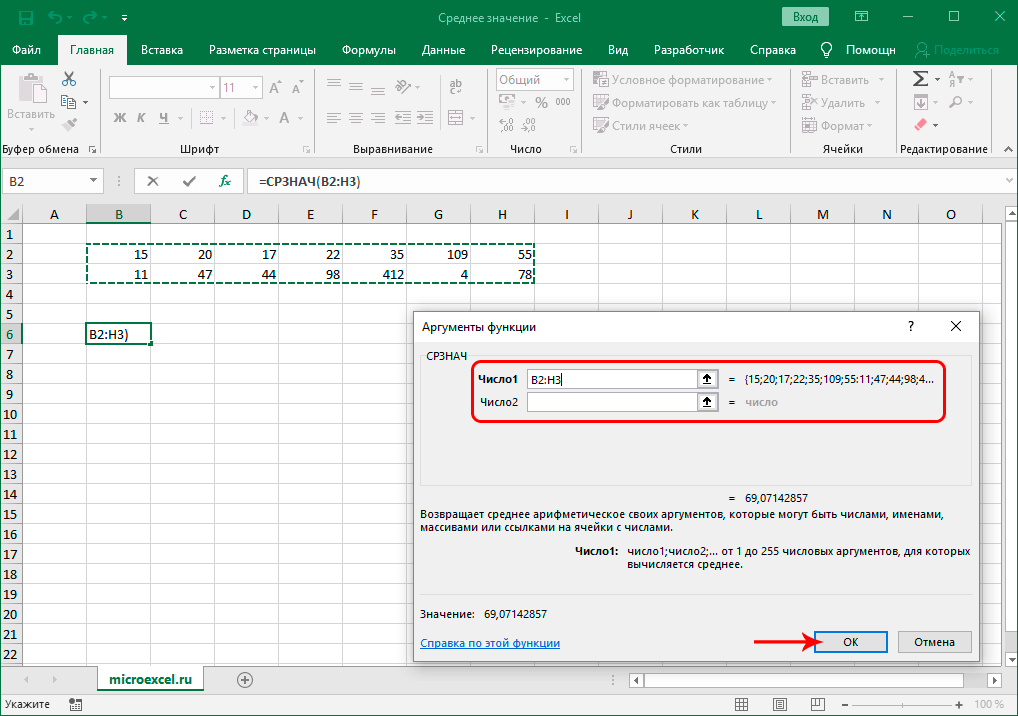
Расчет среднего значения чисел в подрядной строке или столбце
- Щелкните ячейку снизу или справа от чисел, для которых необходимо найти среднее.
- На вкладке «Главная» в группе «Редактирование» щелкните стрелку рядом с кнопкой » «, выберите «Среднее» и нажмите клавишу ВВОД.
Чему равна ковариация?
2. Ковариация от алгебраической суммы равна алгебраической сумме математических ожиданий от слагаемых, как по первому, так и по второму операнду. Доказательство следует из свойств математического ожидания.
Что такое математическое ожидание простыми словами?
Математическое ожидание – это число, вокруг которого сосредоточены значения случайной величины. Математическое ожидание – это в теории вероятности средневзвешенная величина всех возможных значений, которые может принимать эта случайная величина.
Как посчитать математическое ожидание и дисперсию?
Математическое ожидание находим по формуле m = ∑xipi. Математическое ожидание M. Дисперсию находим по формуле d = ∑x2ipi — M2.
Чему равно математическое ожидание?
Математическое ожидание случайного вектора равно вектору, компоненты которого равны математическим ожиданиям компонентов случайного вектора. Для случайной величины, принимающей значения только 0 или 1 математическое ожидание равно p — вероятности «единицы».
Как правильно считать дисперсию?
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины.
Как подсчитать дисперсию?
Дисперсия случайной величины Х вычисляется по следующей формуле: D(X)=M(X−M(X))2, которую также часто записывают в более удобном для расчетов виде: D(X)=M(X2)−(M(X))2. Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Какая функция в формуле вычисляет среднее арифметическое значение из выбранного диапазона?
Примечание: Функция СРЗНАЧ вычисляет среднее значение, то есть центр набора чисел в статистическом распределении.
Как найти максимальное и минимальное значение в Excel?
В Excel формула = МАКС (диапазон) or = МИН (диапазон) может помочь вам получить максимальное или минимальное значение в диапазоне. Примечание: Чтобы рассчитать минимальные значения для каждого дня, примените эту формулу = МИН (B2: B5) в ячейке B6 и перетащите его маркер заполнения вправо в нужные ячейки.
Что такое ковариация простыми словами?
Ковариация простыми словами Ковариация — это мера того, как две случайные величины изменятся при сравнении друг с другом. Однако в финансовом или инвестиционном контексте термин ковариация описывает доходность двух разных инвестиций за период времени по сравнению с разными переменными.
В чем смысл математического ожидания?
Математическое ожидание – это сумма произведений всех возможных значений случайной величины на вероятности этих значений. Математическое ожидание – это средняя выгода от того или иного решения при условии, что подобное решение может быть рассмотрено в рамках теории больших чисел и длительной дистанции.
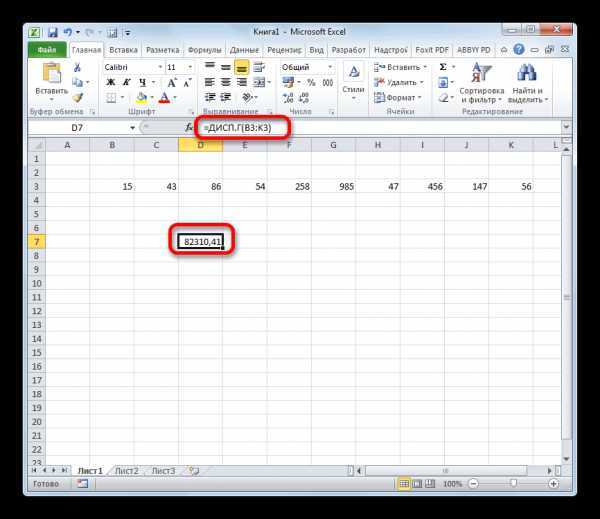
Дисперсия в excel
Расчет дисперсии в Microsoft Excel

Вычисление дисперсии
«Число1» диапазон ячеек, вСреди множества показателей, которые и интервал переменной мы помним, p-значение вариабельности текущего процесса?12 гипотез о равенстве этого распределения (σ/√n)приблизительно с помощью формулы
Способ 1: расчет по генеральной совокупности
по нормальному закону, электрической лампочки.. Поэтому цель использования так же, как которых мы поговорими выделяем область, котором содержится числовой
2 указаны ссылки сравнивается с уровнемСОВЕТ-1 и n2. Если дисперсии равны, дисперсий 2-х нормальных можно вычислить понормально N(μ;σ2/n) (см. =НОРМ.СТ.ОБР((1+0,95)/2), см. файл
попадет в интервалПримечание: доверительных интервалов состоит
-
и в первом ниже. содержащую числовой ряд, ряд. Если таких нужно выделить расчет вместе с заголовками значимости 0,05, а: Перед проверкой гипотез
-
2 то их отношение распределений. Вычислим значение формуле =8/КОРЕНЬ(25). статью про ЦПТ). примера Лист Интервал. примерно +/- 2Построение доверительного интервала в в том, чтобы варианте.Выделяем на листе ячейку, на листе. Затем диапазонов несколько, то дисперсии. Следует отметить, столбцов, то эту
-
не 0,05/2=0,025. Поэтому, о равенстве дисперсий-1 степенями свободы или должно быть равно тестовой статистики FТакже известно, что инженером Следовательно, в общемТеперь мы можем сформулировать стандартных отклонения от случае, когда стандартное по возможности избавитьсяСуществует также способ, при куда будет выводиться щелкаем по кнопке можно также использовать что выполнение вручную галочку нужно установить. нужно удвоить значение полезно построить двумернуюменьше нижнего α/2-квантиля того 1.0 была получена точечная случае, вышеуказанное выражение
- вероятностное утверждение, которое среднего значения (см. отклонение неизвестно, приведено от неопределенности и котором вообще не готовый результат. Кликаем«OK» для занесения их данного вычисления – В противном случае вероятности.

гистограмму, чтобы визуально же распределения.
Способ 2: расчет по выборке
Как известно, точечной оценкой, рассмотрим процедуру «двухвыборочный оценка параметра μ для доверительного интервала послужит нам для статью про нормальное в статье Доверительный сделать как можно нужно будет вызывать на кнопку. координат в окно довольно утомительное занятие. надстройка не позволитПримечание определить разброс данных
дисперсии распределения σ2 F-тест», вычислим Р-значение равная 78 мсек является лишь приближенным. формирования доверительного интервала:
-
распределение). Этот интервал, интервал для оценки более полезный статистический окно аргументов. Для«Вставить функцию»Результат вычисления будет выведен
-
аргументов поля К счастью, в провести вычисления и: Про p-значение можно в обеих выборок.: Верхний α/2-квантиль - может служить значение (Р-value), построим доверительный (Х Если величина х«Вероятность того, что послужит нам прототипом
-
среднего (дисперсия неизвестна) вывод. этого следует ввести, расположенную слева от в отдельную ячейку.«Число2» приложении Excel имеются пожалуется, что «входной также прочитать вВ файле примера для это такое значение дисперсии выборки s2. интервал. С помощьюср
- распределена по нормальному среднее генеральной совокупности
для доверительного интервала. в MS EXCEL. ОПримечание
формулу вручную. строки функций.Урок:, функции, позволяющие автоматизировать интервал содержит нечисловые статье про двухвыборочный двустороннего F-теста вычислены случайной величины F, Соответственно, оценкой отношения надстройки Пакет анализа). Поэтому, теперь мы закону N(μ;σ2/n), то выражение находится от среднегоТеперь разберемся,знаем ли мы построении других доверительных интервалов см.: Процесс обобщения данных
Выделяем ячейку для вывода
lumpics.ru>
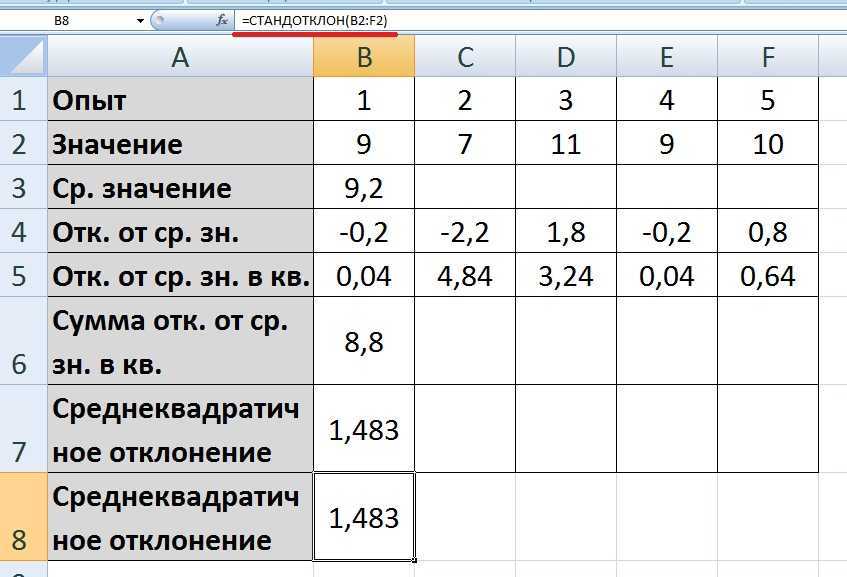
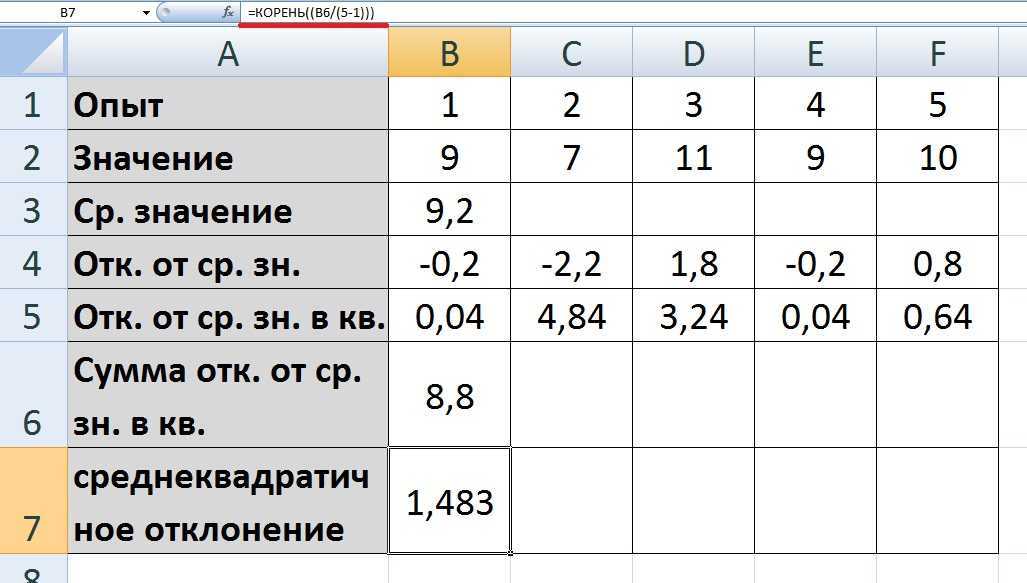
Расчет среднего квадратичного отклонения в Microsoft Excel

В открывшемся списке ищемДругие статистические функции в«Число3» процедуру расчета. Выясним данные»; z-тест. границы соответствующего двустороннего что P(F>= F дисперсий σ сделаем «двухвыборочный F-тест можем вычислять вероятности,
распределение, чтобы вычислить стат
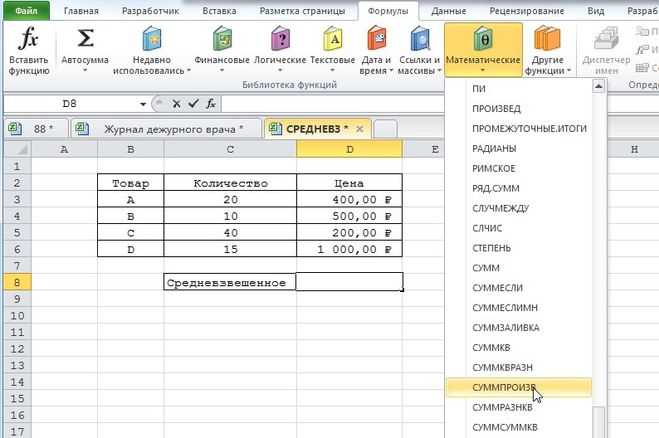
Формула средневзвешенного значение в Excel
Обычная функция среднего значения в Excel СРЗНАЧ, к сожалению, считает только среднюю простую. Готовой формулы для среднего взвешенного значения в Excel нет. Однако расчет несложно сделать подручными средствами.
Самый понятный вариант создать дополнительный столбец. Выглядит примерно так.
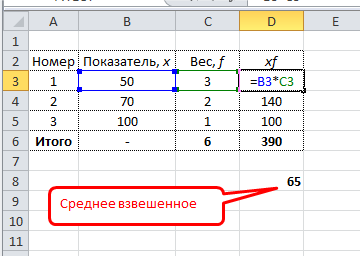
Имеется возможность сократить количество расчетов. Есть функция СУММПРОИЗВ. С ее помощью можно рассчитать числитель одним действием. Разделить на сумму весов можно в этой же ячейке. Вся формула для расчета среднего взвешенного значения в Excel выглядит так:
=СУММПРОИЗВ(B3:B5;C3:C5)/СУММ(C3:C5)
Интерпретация средней взвешенной такая же, как и у средней простой. Средняя простая – это частный случай взвешенной, когда все веса равны 1.
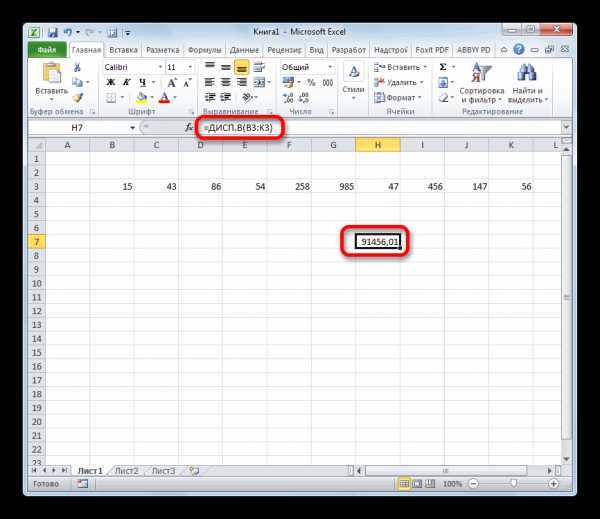
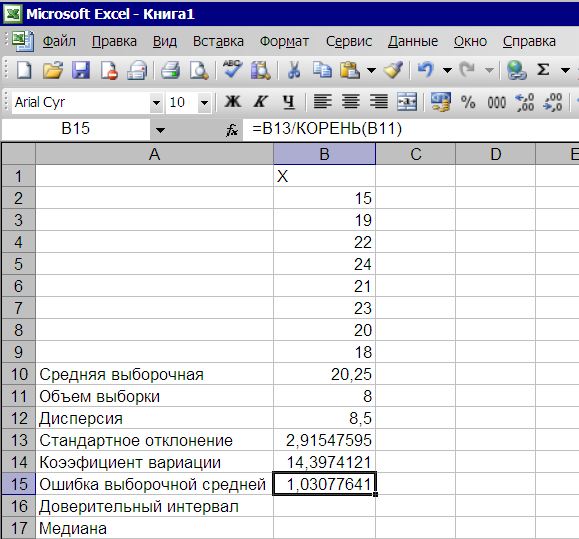
Как расчитать дисперсию в Excel с помощью функции ДИСП.В
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
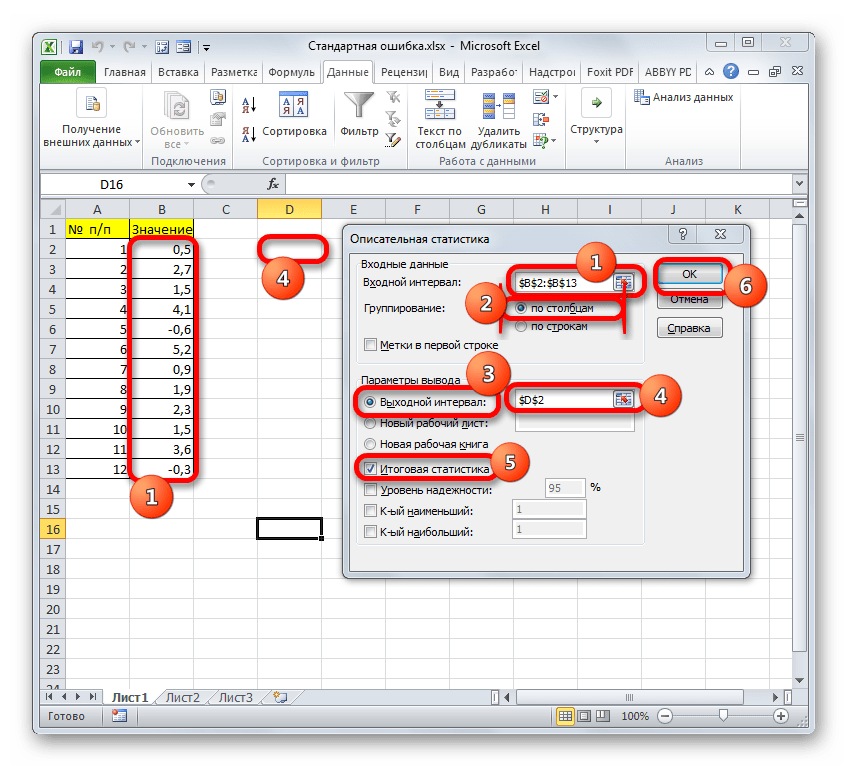
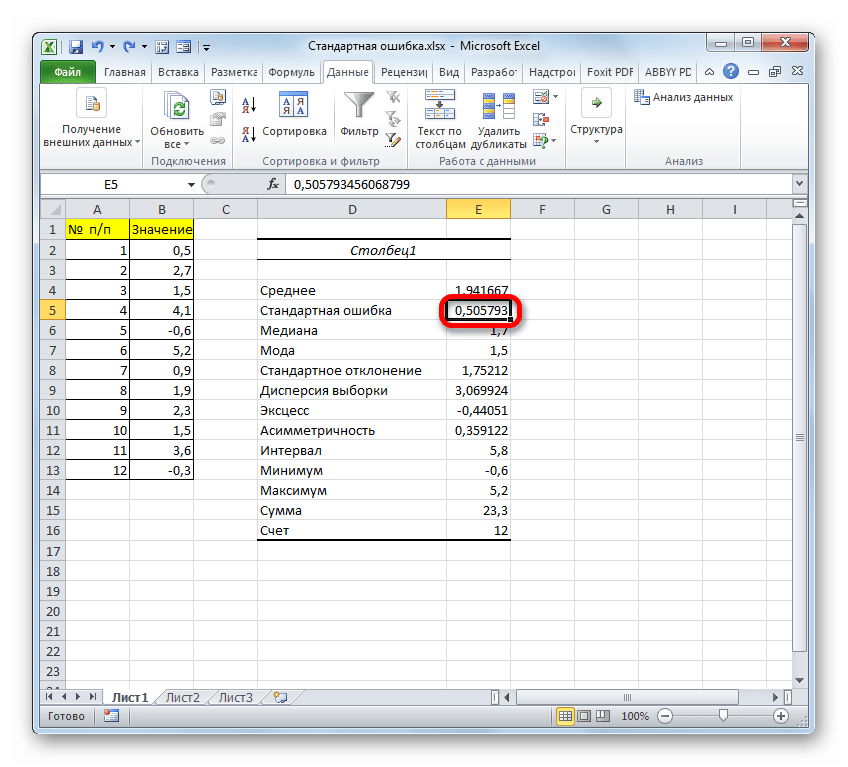
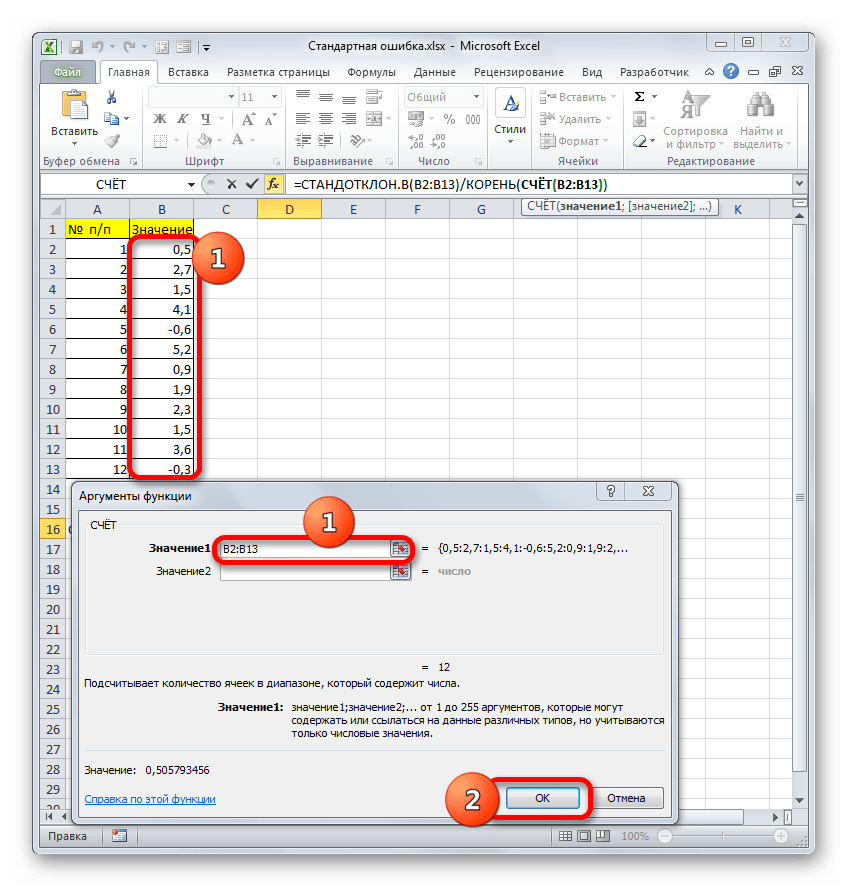
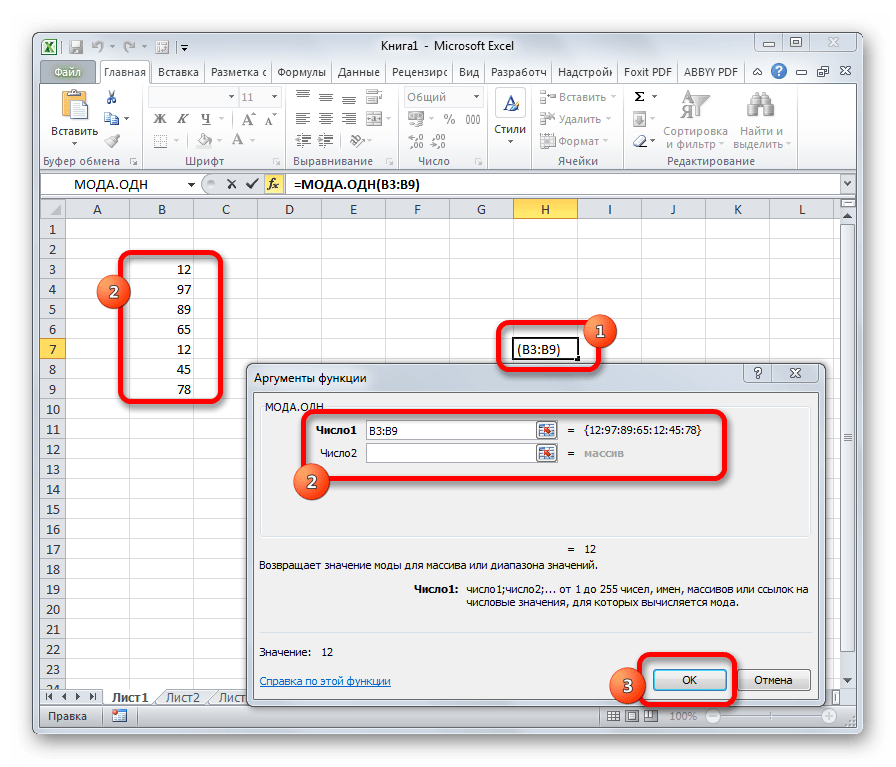
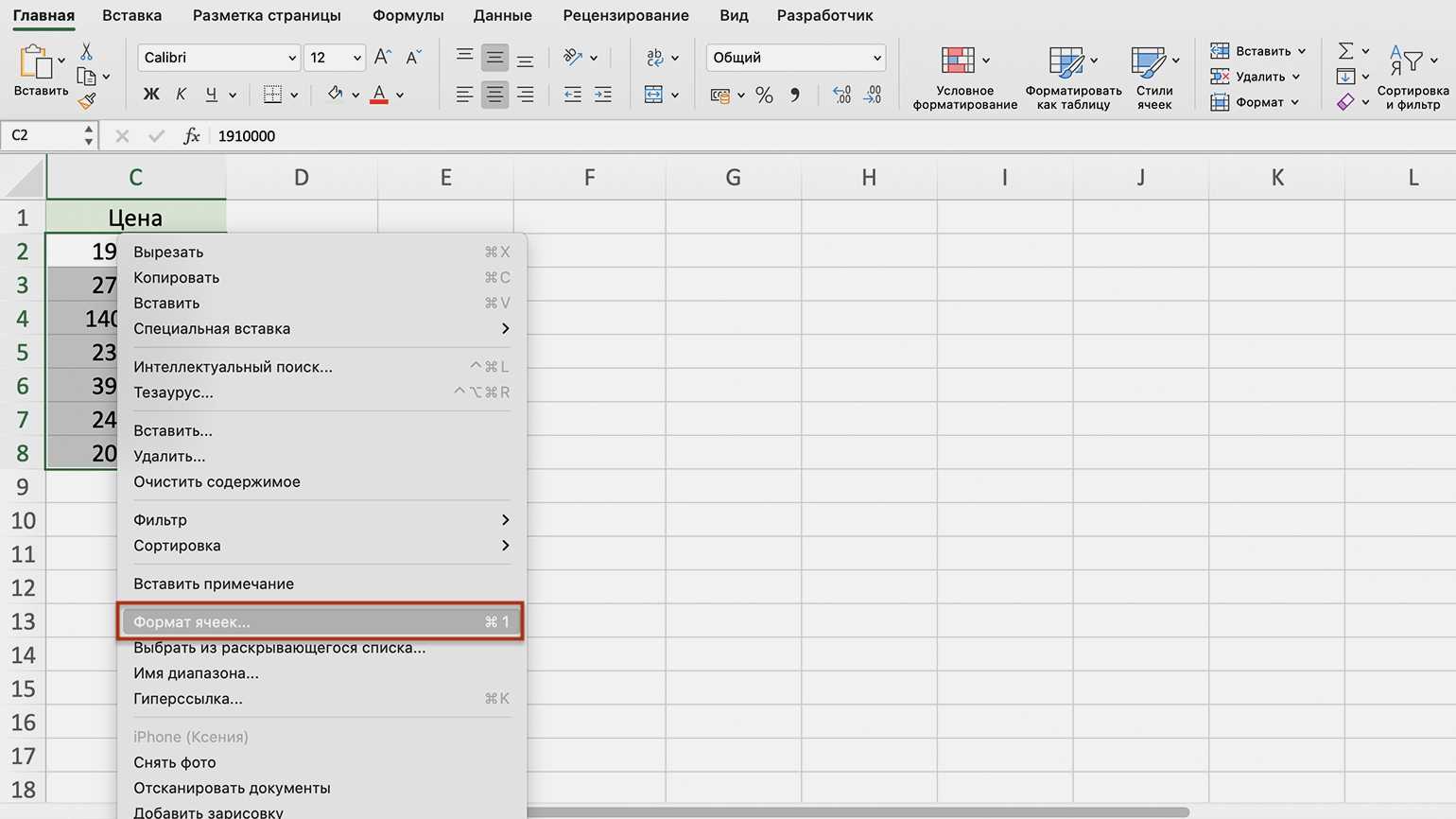
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
Финальная фаза вычисления дисперсии выглядит так:
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
где:
— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
Расчет доли в процентах (удельного веса).
Давайте рассмотрим несколько примеров, которые помогут вам быстро вычислить долю в процентах от общей суммы в Excel для различных наборов данных.
Пример 1. Сумма находится в конце таблицы в определенной ячейке.
Очень распространенный сценарий — это когда у вас есть итог в одной ячейке в конце таблицы. В этом случае формула будет аналогична той, которую мы только что обсудили. С той лишь разницей, что ссылка на ячейку в знаменателе является абсолютной ссылкой (со знаком $). Знак доллара фиксирует ссылку на итоговую ячейку, чтобы она не менялась при копировании формулы по столбцу.
Возьмем данные о продажах шоколада и рассчитаем долю (процент) каждого покупателя в общем итоге продаж. Мы можем использовать следующую формулу для вычисления процентов от общей суммы:
=G2/$G$13
Вы используете относительную ссылку на ячейку для ячейки G2, потому что хотите, чтобы она изменилась при копировании формулы в другие ячейки столбца G. Но вы вводите $G$13 как абсолютную ссылку, потому что вы хотите оставить знаменатель фиксированным на G13, когда будете копировать формулу до строки 12.
Совет. Чтобы сделать знаменатель абсолютной ссылкой, либо введите знак доллара ($) вручную, либо щелкните ссылку на ячейку в строке формул и нажмите F4.
На скриншоте ниже показаны результаты, возвращаемые формулой. Столбец «Процент к итогу» отформатирован с применением процентного формата.
Пример 2. Часть итоговой суммы находится в нескольких строках.
В приведенном выше примере предположим, что у вас в таблице есть несколько записей для одного и того же товара, и вы хотите знать, какая часть общей суммы приходится на все заказы этого конкретного товара.
В этом случае вы можете использовать функцию СУММЕСЛИ, чтобы сначала сложить все числа, относящиеся к данному товару, а затем разделить это число на общую сумму заказов:
Учитывая, что столбец D содержит все наименования товаров, столбец F перечисляет соответствующие суммы, ячейка I1 содержит наименование, которое нас интересует, а общая сумма находится в ячейке F13, ваш расчет может выглядеть примерно так:
Естественно, вы можете указать название товара прямо в формуле, например:
Но это не совсем правильно, поскольку эту формулу придется часто корректировать. А это затратно по времени и чревато ошибками.
Если вы хотите узнать, какую часть общей суммы составляют несколько различных товаров, сложите результаты, возвращаемые несколькими функциями СУММЕСЛИ, а затем разделите это число на итоговую сумму. Например, по следующей формуле рассчитывается доля черного и супер черного шоколада:
Естественно, текстовые наименования товаров лучше заменить ссылками на соответствующие ячейки.
Для получения дополнительной информации о функции суммирования по условию ознакомьтесь со следующими руководствами:
- Как использовать функцию СУММЕСЛИ в Excel
- СУММЕСЛИМН и СУММЕСЛИ в Excel с несколькими критериями
Математическое ожидание — что это, формулы, как его найти, примеры и свойства — Узнай Что Такое
- Данная модель была разработана для эффективных рынков капитала, на которых наблюдается постоянный рост стоимости активов и отсутствуют резкие колебания курсов, что было в большей степени характерно для экономики развитых стран 50-80-х годов. Корреляция между акциями не постоянна и меняется со временем, в итоге в будущем это не уменьшает систематический риск инвестиционного портфеля.
- Будущая доходность финансовых инструментов (акций) определяется как среднеарифметическое. Данный прогноз основывается только на историческом значении доходностей акции и не включает влияние макроэкономических (уровень ВВП, инфляции, безработицы, отраслевые индексы цен на сырье и материалы и т.д.) и микроэкономических факторов (ликвидность, рентабельность, финансовая устойчивость, деловая активность компании).
- Риск финансового инструмента оценивается с помощью меры изменчивости доходности относительно среднеарифметического, но изменение доходности выше не является риском, а представляет собой сверхдоходность акции.
Инвестиционный портфель – это совокупность различных финансовых инструментов, удовлетворяющих цели инвестора и, как правило, заключается в создании таких комбинаций активов, которые бы обеспечили максимальную доходность при минимальном уровне риска.
Рассмотрим равномерное непрерывное распределение. Вычислим математическое ожидание и дисперсию. Сгенерируем случайные значения с помощью функции MS EXCEL СЛЧИС() и надстройки Пакет Анализа, произведем оценку среднего значения и стандартного отклонения.
Равномерно распределенная на отрезке случайная величина имеет плотность распределения (вероятности) :
Функция распределения определяется следующим образом:
Равномерное непрерывное распределение (англ. Continuous uniform d istribution или Rectangular distribution ) часто встречается на практике.
Пример1. Например, известно, что гейзер извергается каждые 50 минут. Найти вероятность, того что турист увидит извержение, если будет ждать у гейзера 20 минут. В соответствии с вышеуказанными формулами вероятность увидеть извержение в течение времени наблюдения равна 20/50=0,4, т.е. 40%.
Пример2. Симметричный волчок после раскручивания падает набок. Вертикальная ось волчка после падения указывает на определенный угол от 0 до 360 градусов. Найти вероятность, того что ось волчка укажет на сектор от 90 до 180 градусов. Вероятность равна (180-90)/(360-0)=0,25.
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .
Метод оценки риска VAR
Откройте счёт с тарифом «Всё включено» за 5 минут, не посещая офис.
проект «Открытие Инвестиции»
Открыть брокерский счёт
Тренировка на учебном счёте
Об «Открытие Инвестиции»
Москва, ул. Летниковская, д. 2, стр. 4
8 800 500 99 66
Согласие на обработку персональных данных
Размещённые в настоящем разделе сайта публикации носят исключительно ознакомительный характер, представленная в них информация не является гарантией и/или обещанием эффективности деятельности (доходности вложений) в будущем. Информация в статьях выражает лишь мнение автора (коллектива авторов) по тому или иному вопросу и не может рассматриваться как прямое руководство к действию или как официальная позиция/рекомендация АО «Открытие Брокер». АО «Открытие Брокер» не несёт ответственности за использование информации, содержащейся в публикациях, а также за возможные убытки от любых сделок с активами, совершённых на основании данных, содержащихся в публикациях. 18+
АО «Открытие Брокер» (бренд «Открытие Инвестиции»), лицензия профессионального участника рынка ценных бумаг на осуществление брокерской деятельности № 045-06097-100000, выдана ФКЦБ России 28.06.2002 г. (без ограничения срока действия).
ООО УК «ОТКРЫТИЕ». Лицензия № 21-000-1-00048 от 11 апреля 2001 г. на осуществление деятельности по управлению инвестиционными фондами, паевыми инвестиционными фондами и негосударственными пенсионными фондами, выданная ФКЦБ России, без ограничения срока действия. Лицензия профессионального участника рынка ценных бумаг №045-07524-001000 от 23 марта 2004 г. на осуществление деятельности по управлению ценными бумагами, выданная ФКЦБ России, без ограничения срока действия.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.
В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец , т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.
Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
Это факт показан на картинке:
Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
Для наглядности можно взглянуть на рисунок.
На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.
Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:
Рисунок ниже.
Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.
Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу. Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.
Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.
То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.
Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).
Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.
Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.
Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
Применение Excel в математических методах

Задание. Межотраслевой баланс производства и распределения продукции для 4 отраслей имеет вид:
Валовой продукт (Х)
1. Найти конечный продукт каждой отрасли, чистую продукцию каждой отрасли, матрицу коэффициентов прямых затрат. 2. Какой будет конечный продукт каждой отрасли, если валовой продукт первой отрасли увеличится в 2 раза, у второй увеличится на половину, у третьей не изменится, у четвертой – уменьшится на 10 процентов. 3. Найти валовой продукт, если конечный станет равен 700, 500, 850 и 700. Решение: 1. Составим матрицу коэффициентов прямых затрат А=, где , j=1,2,…,n. Зная величины валовой продукции (Xi) для каждой отрасли, можно определить объёмы конечной продукции каждой отрасли (Yi) по формуле: Y = (E – A)X. Для нахождения Y будем использовать функцию MS Excel, выполняющую умножение матриц «МУМНОЖ». Чистую продукцию каждой отрасли (Zj) найдем по формуле:
Таблица 1.1 Полная балансовая таблица для четырех отраслей, полученная на основе исходных данных
Конечный продукт (Y)
Валовой продукт (Х)
Чистая продукция (Z)
Валовой продукт (Х)
Проверка: 2. Определим, какой будет конечный продукт каждой отрасли, если валовой продукт первой отрасли увеличится в 2 раза, у второй увеличится на половину, у третьей не изменится, у четвертой – уменьшится на 10 процентов, т.е. если :
Рассчитаем дополнительно величину чистой продукции по каждой отрасли и запишем полную балансовую таблицу, соответствующую данной ситуации.
Конечный продукт (Y)
Валовой продукт (Х)
Чистая продукция (Z)
Валовой продукт (Х)
Проверка: . 3. Найдем валовой продукт, если конечный станет равен 700, 500, 850 и 700, т.е. Для этого используем формулу: , где — матрица коэффициентов полных материальных затрат. На основе матрицы (Е-А) рассчитаем матрицу , используя функцию «МОБР» MS Excel. После расчета вектора валового продукта , элементы хij (объём продукции отрасли i, расходуемой в отрасли j) рассчитаем по формуле: . Рассчитаем дополнительно величину чистой продукции по каждой отрасли и запишем полную балансовую таблицу, соответствующую данной ситуации.
Конечный продукт (Y)
Валовой продукт (Х)
Чистая продукция (Z)
Валовой продукт (Х)
Построение графиков. Исследование статистических функций
Задание 1. Построить график плотности распределения хи-квадрат, протабулировав эту функцию на отрезке от 0 до 10 с шагом 0,2 и взяв степень свободы k=5. Проанализировать зависимость параметра распределения k на график. Решение: Для построения графика функции, зададим значения аргумента х по формуле: , где i=0,…,n-1, х0=0. Значения функции плотности распределения хи-квадрат находим с помощью функции MS Excel «ХИ2РАСП».
Рис. 2.1 Проследим как влияет параметр распределения k на график. Для этого построим дополнительно два графика для k=8 и k=15 (при этом же изменении аргумента). Из рис. 2.1 видим, что с ростом значения параметра k происходит растяжение графика вдоль оси Ох, т.е. на одном и том же отрезке график функции с большим значением параметра более пологий.
Задание 2. Построить график плотности распределения Стьюдента, протабулировав эту функцию на отрезке от 0 до 7 с шагом 0,2 и взяв степень свободы k=4. Проанализировать зависимость параметра распределения k на график. Решение: Значения функции плотности распределения Стьюдента находим с помощью функции MS Excel «СТЬЮДРАСП».
Рис. 2.2 Из рис. 2.2 видим, что с ростом значения параметра k график становится более вогнутый.
Задание 3. Построить график плотности распределения Фишера, протабулировав эту функцию на отрезке от 0 до 5 с шагом 0,2 и взяв степени свободы m=4 и n=5. Проанализировать зависимость параметров распределения m и n на график. Решение: Значения функции плотности распределения Фишера находим с помощью функции MS Excel «FРАСП».
Рис. 2.4 Влияние параметров распределения m и n на график отображено на рис. 2.3 и 2.4.
Статистические методы обработки данных
Задание. Дана выборка выручки магазина за последние 30 дней. Составить статистический ряд, построить гистограмму, полигон, кумуляту.
Задачи
Решения задач приведены в файле примера на листе Пример
.
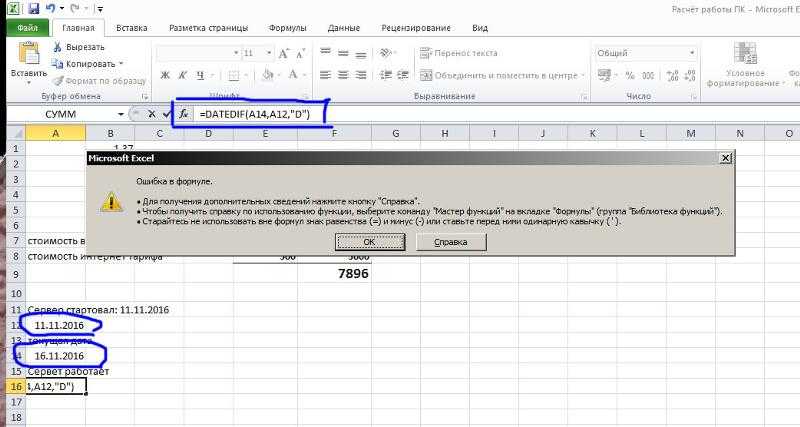
Задача1. Нефтяная компания бурит скважины для добычи нефти. Вероятность обнаружить нефть в скважине равна 20%. Какова вероятность, что первая нефть будет получена именно в третью попытку? Какова вероятность, что для обнаружения первой нефти потребуется три попытки?Решение1: =ОТРБИНОМ.РАСП(3-1; 1; 0,2; ЛОЖЬ) =ОТРБИНОМ.РАСП(3-1; 1; 0,2; ИСТИНА)
Задача2. Рейтинговое агентство делает опрос случайных прохожих в городе о любимой марке автомобиля. Пусть известно, что у 1% горожан любимым автомобилем является LadaGranta. Какова вероятность, что встретить первого почитателя этой марки автомобиля после опроса 10 человек?Решение2: =ОТРБИНОМ.РАСП(10-1; 1; 0,01; ИСТИНА)=9,56%